Uncovering Customer Insights with Topic Modeling in Python

Introduction
In today’s digital era, businesses receive vast amounts of customer feedback in the form of reviews, social media comments, and support tickets. Manually analyzing these texts can be overwhelming. This is where Topic Modeling using Latent Dirichlet Allocation (LDA) comes in handy. It helps uncover hidden themes in textual data, enabling businesses to make data-driven decisions.
In this article, I’ll explore how to use Gensim’s LDA to analyze customer reviews from an e-commerce store, extract meaningful topics, and gain insights into customer concerns.
Understanding Topic Modeling with LDA
Latent Dirichlet Allocation (LDA) is a popular unsupervised learning technique that assumes:
- Each document (review) is a mixture of multiple topics.
- Each topic is a mixture of specific words with different probabilities.
By applying LDA to customer reviews, we can categorize feedback into meaningful themes, such as battery life issues, product performance, or design feedback.
Example Scenario: Analyzing Customer Reviews
Step 1: Sample Customer Reviews
Consider a dataset of customer reviews from an e-commerce store selling electronic gadgets:
reviews = [
"The battery life of this phone is amazing. Lasts all day!",
"The laptop is very slow and keeps crashing. Poor performance.",
"This smartphone has an excellent camera but the battery drains fast.",
"The sound quality of these headphones is top-notch!",
"I love the design of this laptop, but the keyboard is not comfortable.",
"The phone heats up too quickly when playing games.",
"Amazing laptop for the price. Fast performance and great battery life."
]Step 2: Preprocessing the Text Data
First I tokenize the text, remove stopwords, and convert words to lowercase for effective modeling:
1. Tokenization:
Tokenization is the process of breaking down text into individual words or tokens. It’s a key step because:
- Simplifies text processing: By splitting the text into smaller, manageable units, tokenization allows algorithms to process each word independently, making it easier to analyze patterns, frequencies, and relationships between words.
- Facilitates feature extraction: In many ML algorithms, the input data needs to be in the form of discrete features. Tokenization helps convert raw text into these discrete features.
- Improves text representation: By splitting text into tokens, it becomes possible to represent it numerically (such as using techniques like TF-IDF or word embeddings), which ML models can work with.
2. Stopwords Removal:
Stopwords are common words like “the,” “is,” “and,” “to,” etc., that don’t contribute meaningful information for text analysis. Removing them is beneficial for several reasons:
- Reduces noise: Stopwords are frequent but carry little value in determining the meaning of the text. Removing them helps the model focus on more important words that are relevant for tasks like sentiment analysis, text classification, etc.
- Improves computational efficiency: Removing unnecessary stopwords reduces the size of the data, leading to faster processing, lower memory usage, and improved model performance.
- Enhances model accuracy: By eliminating words that are not informative, models can better capture the true essence of the text, leading to better predictions or analysis.
Tokenization breaks text into manageable parts for easier analysis, while stopword removal ensures that the focus stays on meaningful content, both improving model accuracy and efficiency in ML text analytics.
import gensim
from gensim import corpora
from gensim.models import LdaModel
from gensim.parsing.preprocessing import STOPWORDS
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
nltk.download('punkt_tab')
# Tokenize and remove stopwords
processed_reviews = [[word.lower() for word in word_tokenize(review) if word.lower() not in STOPWORDS] for review in reviews]Step 3: Convert Text to Numerical Format
LDA requires numerical input, so I have create a dictionary and convert the text to a bag-of-words representation:
# Create a dictionary mapping words to unique IDs
dictionary = corpora.Dictionary(processed_reviews)
# Convert reviews to bag-of-words format
corpus = [dictionary.doc2bow(review) for review in processed_reviews]Step 4: Train the LDA Model
I have set the number of topics (e.g., num_topics=2) and train the model:
num_topics = 2 # Assuming two main themes in the reviews
lda_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topics, passes=10, random_state=42)Step 5: Extract and Interpret Topics
After training, print the most significant words in each topic:
for idx, topic in lda_model.print_topics():
print(f"Topic {idx}: {topic}\n")Example Output:
Topic 0: 0.200*"battery" + 0.150*"phone" + 0.120*"life" + 0.100*"camera" + 0.090*"drains"
Topic 1: 0.180*"laptop" + 0.140*"performance" + 0.110*"slow" + 0.100*"keyboard" + 0.090*"design"Step 6: Visualizing Topics
To better understand the topics, I used pyLDAvis library to visualize them interactively:
!pip install pyLDAvis
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
import matplotlib.pyplot as plt
# Prepare the visualization
lda_display = gensimvis.prepare(lda_model, corpus, dictionary)
# Display the visualization
pyLDAvis.display(lda_display)Example Visualization Output:
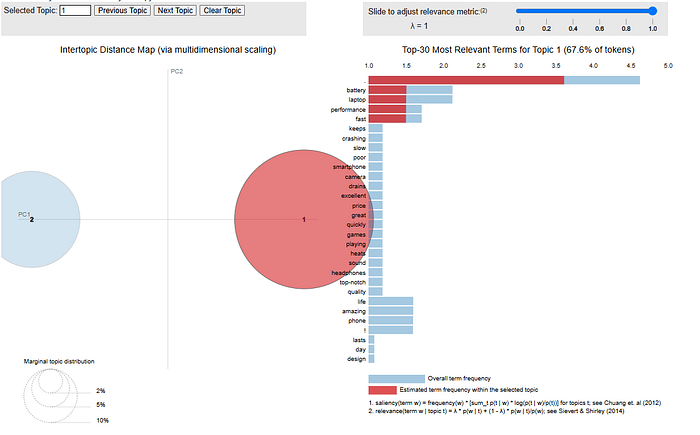
This visualization will display topics as bubbles, where:
- The size of a bubble represents the importance of a topic.
- Words associated with each topic appear in a ranked list.
By interacting with the visualization, businesses can explore dominant topics, their word distributions, and relationships between topics effectively.
Business Insights from Topic Modeling
By analyzing the discovered topics, we can gain valuable insights:
✅ Battery and Phone Issues: Customers frequently mention words like “battery,” “phone,” and “drains,” indicating concerns about battery life in smartphones.
✅ Laptop Performance Feedback: Words like “performance,” “slow,” and “keyboard” suggest customers are discussing laptop speed and usability.
How Businesses Can Use These Insights:
✔️ Improve Product Features: If many reviews mention “battery drains fast,” manufacturers can focus on improving battery performance.
✔️ Enhance Customer Support: If “slow performance” appears frequently, providing troubleshooting guides or software updates can help.
✔️ Boost Marketing Strategies: Positive reviews about “amazing camera” or “top-notch sound quality” can be highlighted in product advertisements.
Conclusion
In this article, I demonstrated how LDA topic modeling helps uncover hidden themes in customer reviews. By leveraging Gensim’s LDA, businesses can extract valuable insights, improve products, and enhance customer satisfaction.